Qualcomm's latest flagship is here - and we're on board
Published
By Elina Norling

Qualcomm’s latest flagship SoC is the Snapdragon 8 Elite. It brings the Oryon CPU to mobile and combines it with a faster Hexagon NPU and an AI-enabled ISP – all built for multimodal workloads running on-device. We’re very impressed by its performance and our in-house testing suggests it’s definitely one of the fastest AI accelerators on the market for certain workloads. You can also test its performance on your own model using the embedl-hub library today.
In this post, we explore some of the new chip’s performance. With the embedl-hub library, we ran a set of carefully selected models, collected benchmark results, and compared the performance against other popular chips.
What’s new in Snapdragon 8 Elite
In Qualcomm’s own words, Snapdragon 8 Elite is the most advanced platform in the 8-series to date. It introduces a new Adreno GPU architecture and an AI enabled ISP that works closely with the Hexagon NPU to support on-device generative and multimodal AI, including live camera prompts. On the connectivity side, Wi Fi 7 and advanced 5G provide headroom for hybrid edge to cloud workflows. Notably, the chipset is already featured in – and confirmed for – several flagship devices such as the Samsung Galaxy S25 series, OnePlus 13, Xiaomi 15 Ultra, Realme GT 7 Pro, and Asus ROG Phone 9, with more OEMs poised to launch devices soon.
For edge AI developers, the implications are practical. Prime Oryon cores reach 4.32 GHz with about 45% higher CPU performance at roughly 44% better power efficiency, while the Hexagon NPU adds Direct Link, Micro Tile Inferencing, large shared memory concurrency, and mixed precision across INT4, INT8, INT16, and FP16. The tighter camera to NPU path improves data locality and end-to-end latency. In short, 8 Elite delivers more usable compute for quantized models and steadier sustained throughput.
Fresh numbers from Embedl hub
We’ve benchmarked 8 Elite with the embedl-hub library and below follows the result. We put the NPU on the Snapdragon 8 Elite to the test against the most powerful embedded GPU on the market today, the NVIDIA AGX Jetson Orin (awaiting the AGX Thor release), the less powerful NVIDIA Jetson Orin Nano, and finally the 8 Elite’s two generational predecessors, Snapdragon 8 gen 3 and gen 2.
We chose a combination of three image classification and popular backbone models to capture a representative mix of architectures for the Snapdragon 8 Elite. ConvNeXt_Tiny is a standard convolutional model, showing how the chip handles conv-heavy model architectures. EfficientNet_v2_S is a compound-scaled convolutional network designed for both accuracy and efficiency on resource constrained devices. It was benchmarked with higher input resolution, stressing memory and bandwidth, and showing how the chip’s performance scales with input size. Finally, Swin_v2_Tiny provides an architectural contrast with a transformer backbone, highlighting performance on attention-heavy compute under identical settings.
All benchmarks were performed in INT8 precision and batch size 1. The image size was 224x224 for ConvNext_Tiny and Swin_v2, and 384x384 for EFficientNet_v2_S.
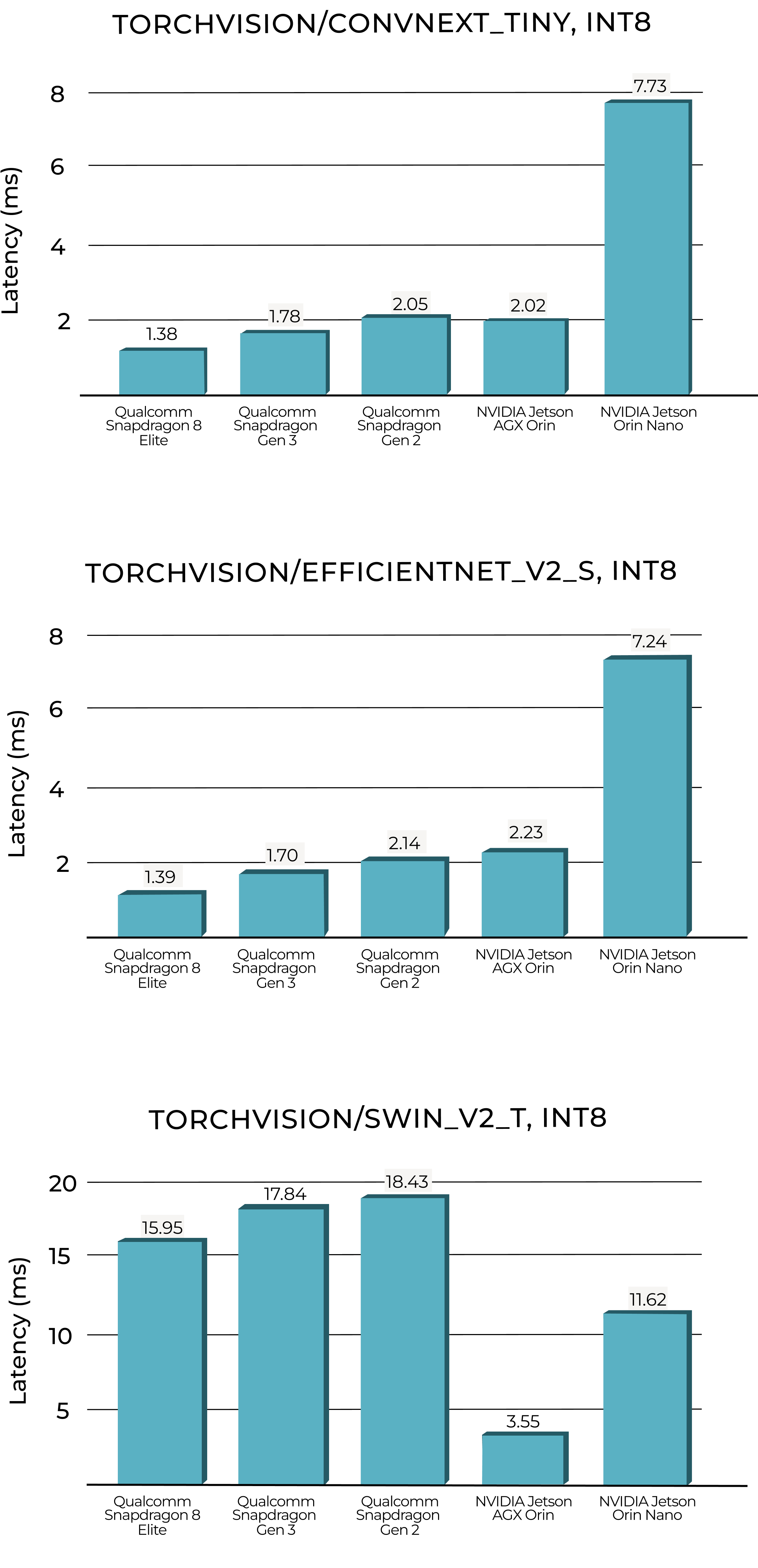
Looking at the figures of the two conv-heavy benchmarks, we see that NPU on the Snapdragon 8 Elite outperforms both Jetson GPUs and its predecessors. For these network architectures, the GPUs cannot leverage its full parallel processing power and the NPU’s ability to execute sequential operations with speed gives it a clear advantage. The Snapdragon 8 Elite is really blazingly fast for this type of model architecture; those characterized by model depth rather than model width. There is also a clear performance boost compared to previous generations of Snapdragon 8s. Assuming they run similar software, this highlights the improved accelerator design in the latest version of the Hexagon NPU.
For the Swin_v2_Tiny, where the compute time is dominated by the attention layers, there are still clear generational gains over the older Snapdragon chips. However, the ability to execute computations in parallel on the GPU make the AGX Orin and Nano outperform the mobile NPUs significantly. One could argue that two powerful embedded GPUs is not a fair comparison to the mobile SoC operating on a much lower power budget, but given the lightning speed of the Snapdragon 8 Elite we felt the need to figure out just how powerful it really is by giving it a real challenge.
We also note that the 8 Elite have hardware support for INT4 computations. Software support is still lagging but it’s changing rapidly. For applications that can sustain such heavy compression, the Snapdragon 8 Elite will provide significant performance gains and we expect INT4 execution to play a major role in bringing cloud applications to the edge in the near future. Quantization is one of our favourite topics at Embedl, feel free to come talk to us about it on Slack.
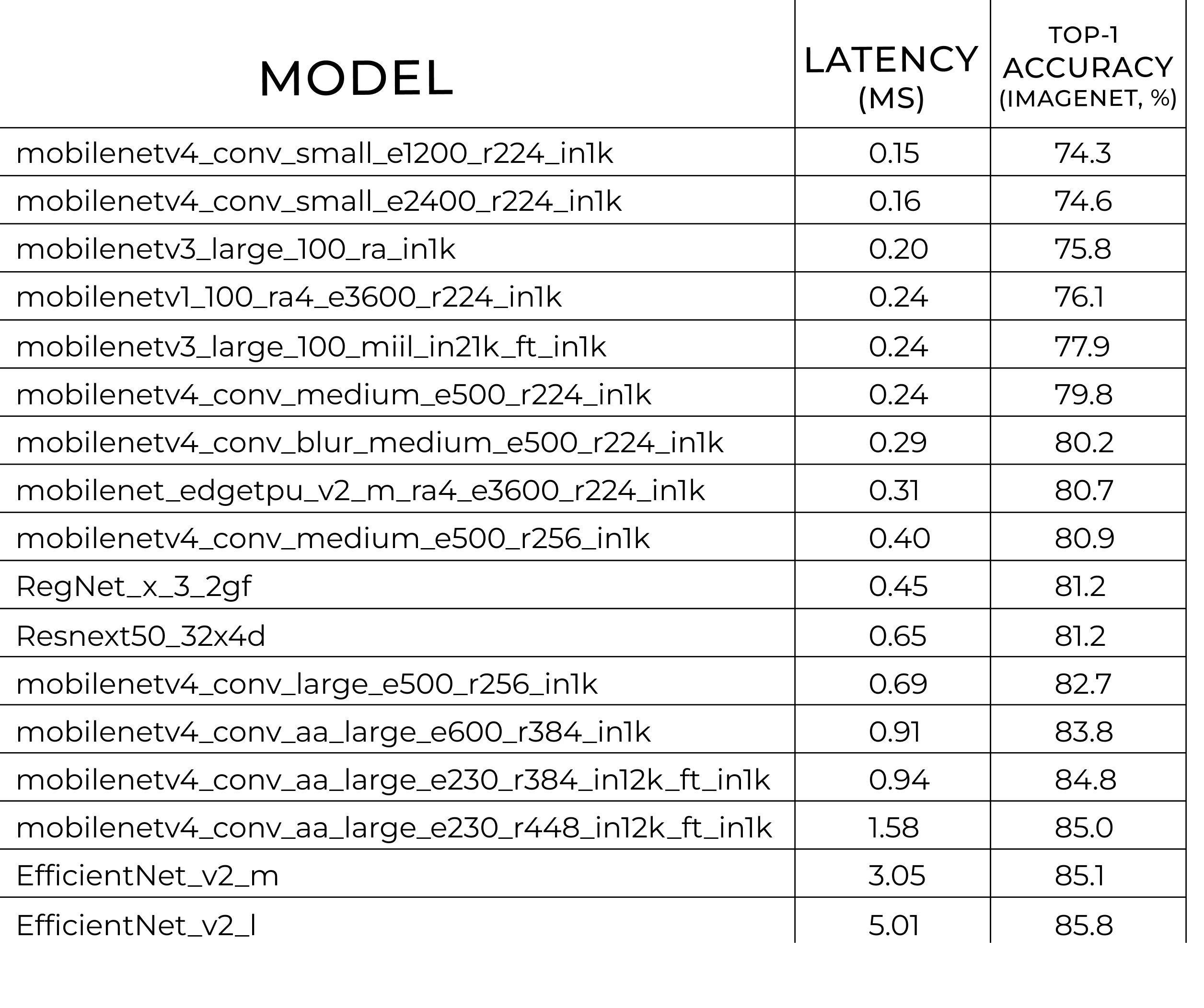
We also examined which models are best suited to Snapdragon 8 Elite with our benchmark suite. According to the table below, the following models are Pareto optimal with respect to Latency (ms) and Top-1 Accuracy on the ImageNet dataset. To find the pareto optimal models we benchmarked the entire timm and Torchvision model libraries. It’s noteworthy that the Mobilenet V4 model architecture is down below 0.2 ms. So if speed is your only concern, the Mobilenet architecture should be high up your list. It’s not surprising, however, that an architecture that was designed for mobile devices is highly efficient on exactly that, a mobile device. It’s more surprising that both the Regnet and Resnet architecture, which were originally designed for GPUs, are still very efficient models on the Snapdragon 8 Elite, with performance in the sub ms region.
Support in Embedl Hub
Do you want to see the benchmarks with your own eyes? Do it yourself! Our Python library already supports Snapdragon 8 Elite and other popular chip’s as remote hardwares, so you can verify existing ONNX models – or your own model – on the device and compare which ones are most compatible. Your benchmarks are then visualized on the Embedl Hub platform on your own personal page. Run quantization, compilation, and on-device profiling directly from the terminal with our embedl-hub CLI and put the (according to us) currently hottest chip from Qualcomm to work in your pipeline.
Compile your model for a device powered by the Snapdragon 8 Elite, like the Samsung Galaxy S25:
embedl-hub compile qai-hub \ --model my_model.onnx \ --device "Samsung Galaxy S25" \ --runtime tfliteand submit a benchmark job:
embedl-hub benchmark qai-hub \ --model my_model.tflite \ --device "Samsung Galaxy S25" \If you’re not sure how to best configure your deployments, ask us on Slack.
More devices are coming
Embedl Hub is moving fast. Snapdragon 8 Elite and other Qualcomm chips are already supported, and more edge hardware from top vendors are on the way. Are you interested in early access? Request a device/vendor: